Conversion Options
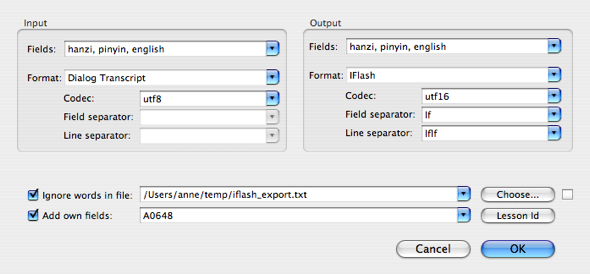
On the Conversion Options panel you can specify how imported text will be converted. Not all of the possible options work, but the main ones do. Please note that your settings are just passed to the real converters on the tabs. You can't convert a dialog transcript from the Vocab CSV tab or vice versa. I don't plan much program intelligence here, you are smart enough to apply the right formats to the different tasks.
Formats
Formats are presets for conversion settings. If you you want to convert a CPod Vocab CSV to an IFlash import file, just choose those formats in the input and the output section. Then specify the Fields. Please note, that the Vocab XML format doesn't work yet. And from IFlash neither (because to newlines aren't really Csv). Don't use it.
Converting to IFlash, works great though. Just choose IFlash as the output format, enter the fields
(most likely they'll be hanzi, pinyin, english). Later in IFlash, open File - Import..., select Multi-Sided Format
and load the IFlash-Importfile created by CPodTools:

I recommend first testing it with a new deck, though.
Fields
The fields specify in which order what data comes in - and goes out.- For the input have a look at your input file. Each field in a line needs a name, even an empty one. You can ignore fields, when there is no other interesting one coming after it. When the input fields are disabled you can quite trust them, if you stay with the proposed option.
- For the output just specify which fields you want to have in your result. Each of them has to exist in the input fields.
Separators
You can specify the field and the line separators for the input and the output. For easier entry and reading I gave some of them alias names. Lf is a Unix linebreak, Cr a Mac linebreak, crlf a windows linebreak, lflf are two Unix linebreaks and should only be used for output. You can enter your own separators here. The most usual are , and ;.
Codecs
Specify the encodings of your input and outputfile. If utf8 and utf16 aren't enough for you, here's a list with the python standard encodings.
Note that UTF-16 input always requires a BOM. I'll play around with that another time. CPod Stuff comes in UTF-8.
Ignore words in file
Ignore words in file: All entries in that file, read line by line, will be ignored during import. Read more about it in chapter Creating Ignore Lists. Take care that the file has to be encoded in UTF-16. IFlash exports UTF-16 files.
Add own fields
Add own fields: In my IFlash deck for sentences I have an extra card side for the source of a sentence. I like to know where it comes from. With the add own fields option I add the Lesson Id as an extra field to the converted output. Each of the imported entries gets those data at the end.
You can add more than one additional field. Just separate them by commas:- first extra field data, second extra field data
Note, that on scraping lesson stuff from the web you can automatically update the added fields to the lesson id. More about that in the Lesson Stuff chapter.